Courage to learn ML: Demystifying L1 & L2 Regularization (part 1)
Comprehend the underlying purpose of L1 and L2 regularization
Welcome to the ‘Courage to learn ML’, where we kick off with an exploration of L1 and L2 regularization. This series aims to simplify complex machine learning concepts, presenting them as a relaxed and informative dialogue, much like the engaging style of “The Courage to Be Disliked,” but with a focus on ML.
These Q&A sessions are a reflection of my own learning path, which I’m excited to share with you. Think of this as a blog chronicling my journey into the depths of machine learning. Your interactions — likes, comments, and follows — go beyond just supporting; they’re the motivation that fuels the continuation of this series and my sharing process.
Today’s discussion goes beyond merely reviewing the formulas and properties of L1 and L2 regularization. We’re delving into the core reasons why these methods are used in machine learning. If you’re seeking to truly understand these concepts, you’re in the right place for some enlightening insights!
In this post, we’ll be answering the following questions:
- What is regularization? Why we need it?
- What is L1, L2 regularization?
- Why do we prefer smaller coefficients over large ones? How do large coefficients equate to increased model complexity?
- Why there are multiple combinations of weights and biases in a neural network?
- Why aren’t bias terms penalized in L1 and L2 regularization?
What is regularization? Why we need it?
Regularization is a cornerstone technique in machine learning, designed to prevent models from overfitting. Overfitting occurs when a model, often too complex, doesn’t just learn from the underlying patterns (signals) in the training data, but also picks up and amplifies the noise. This results in a model that performs well on training data but poorly on unseen data.
What is L1, L2 regularization?
There are multiple ways to prevent overfitting. L1, L2 regularization is mainly addresses overfitting by adding a penalty term on coefficients to the model’s loss function. This penalty discourages the model from assigning too much importance to any single feature (represented by large coefficients), thereby simplifying the model. In essence, regularization keeps the model balanced and focused on the true signal, enhancing its ability to generalize to unseen data.
Wait, why exactly do we impose a penalty on large weights in our models? How do large coefficients equate to increased model complexity?
While there are many combinations that can minimize the loss function, not all are equally good for generalization. Large coefficients tend to amplify both the useful information (signal) and the unwanted noise in the data. This amplification makes the model sensitive to small changes in the input, leading it to overemphasize noise. As a result, it cannot perform well on new, unseen data.
Smaller coefficients, on the other hand, help the model to focus on the more significant, broader patterns in the data, reducing its sensitivity to minor fluctuations. This approach promotes a better balance, allowing the model to generalize more effectively.
Consider an example where a neural network is trained to predict a cat’s weight. If one model has a coefficient of 10 and another a vastly larger one of 1000, their outputs for the next layer would be drastically different — 300 and 30000, respectively. The model with the larger coefficient is more prone to making extreme predictions. In cases where 30lbs is an outlier (which is quite unusual for a cat!), the second model with the larger coefficient would yield significantly less accurate results. This example illustrates the importance of moderating coefficients to avoid exaggerated responses to outliers in the data.
Could you elaborate on why there are multiple combinations of weights and biases in a neural network?
Imagine navigating the complex terrain of a neural network’s loss function, where your mission is to find the lowest point, or a ‘minima’. Here’s what you might encounter:
- A Landscape of Multiple Destinations: As you traverse this landscape, you’ll notice it’s filled with various local minima, much like a non-convex terrain with many dips and valleys. This is because the loss function of a neural network with multiple hidden layers, is inherently non-convex. Each local minima represents a different combination of weights and biases, offering multiple potential solutions.
- Various Routes to the Same Destination: The network’s non-linear activation functions enable it to form intricate patterns, approximating the real underlying function of the data. With several layers of these functions, there are numerous ways to represent the same truth, each way characterized by a distinct set of weights and biases. This is the redundancy in network design.
- Flexibility in Sequence: Imagine altering the sequence of your journey, like swapping the order of biking and taking a bus, yet still arriving at the same destination. Relating this to a neural network with two hidden layers: if you double the weights and biases in the first layer and then halve them in the second layer, the final output remains unchanged. (Note this flexibility, however, mainly applies to activation functions with some linear characteristics, like ReLU, but not to others like sigmoid or tanh). This phenomenon is referred to as ‘scale symmetry’ in neural networks.
I’ve been reading about L1 and L2 regularization and observed that the penalty terms mainly focus on weights rather than biases. But why is that? Aren’t biases also coefficients that could be penalized?
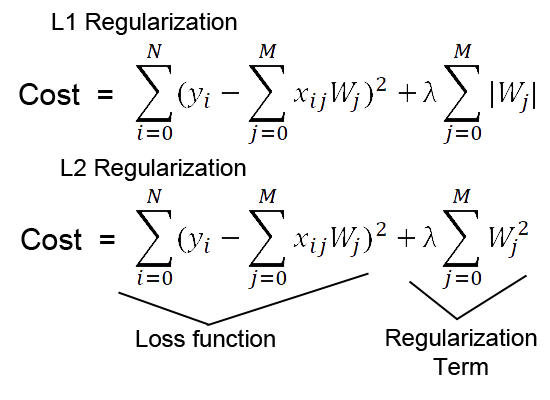
In brief, the primary objective of regularization techniques like L1 and L2 is to predominantly prevent overfitting by regulating the magnitude of the model’s weights (personally, I think that’s why we call them regularizations). Conversely, biases have a relatively modest impact on model complexity, which typically renders the need to penalize them unnecessary.
To understand better, let’s look at what weights and biases do. Weights determine the importance of each feature in the model, affecting its complexity and the shape of its decision boundary in high-dimensional space. Think of them as the knobs that tweak the shape of the model’s decision-making process in a high-dimensional space, influencing how complex the model becomes.
Biases, however, serve a different purpose. They act like the intercept in a linear function, shifting the model’s output independently of the input features.
Here’s the key takeaway: Overfitting occurs mainly because of the intricate interplay between features, and these interactions are primarily handled by weights. To tackle this, we apply penalties to weights, adjusting how much importance each feature carries and how much information the model extracts from them. This, in turn, reshapes the model’s landscape and, as a result, its complexity.
In contrast, biases don’t significantly contribute to the model’s complexity. Moreover, they can adapt as weights change, reducing the need for separate bias penalties.
Now that you’ve gained insight into the existence of multiple sets of weights and biases and the preference for smaller ones, we’re ready to dive deeper.
Join me in the second part of the series, I’ll unravel the layers behind L1 and L2 regularization, offering an intuitive understanding with Lagrange multipliers (don’t worry about the name, it’s a straightforward concept 😃)
See you there!
If you liked this article, feel free to connect with me on LinkedIn for more discussions! 💡 And if you’d like to support my writing (or suggest my next topic), you can buy me a coffee on https://ko-fi.com/amyma101! ☕✨

